AI ประเภทของการแบ่งกลุ่มข้อมูล (Clustering)
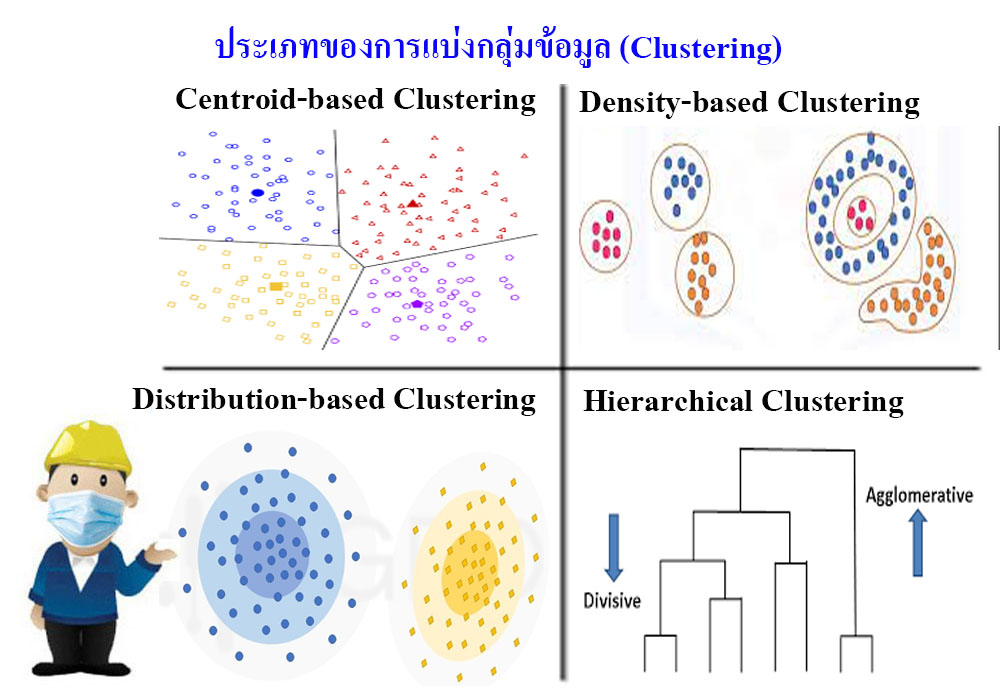
ประเภทของการแบ่งกลุ่มข้อมูล (Clustering Algorithms) มีหลายแนวคิดและประเภทในการทำงาน เช่น
1. การแบ่งกลุ่มข้อมูลจากจุดข้อมูล (Centroid-based Clustering) เป็น การกระจุกตัวของจุดข้อมูลให้ใกล้กับจุดกึ่งกลางของกลุ่ม (Centroid) มากที่สุด การแบ่งกลุ่มแบบนี้มีประสิทธิภาพในบางระดับขึ้นกับเงื่อนไขตั้งต้นและข้อมูลที่เป็นค่าผิดปกติ ซึ่ง algorithm ที่นิยมใช้ คือ k-means เพราะเป็น algorithm ที่ง่ายและมีประสิทธิภาพ โดยมีการทำงานแบบวนซ้ำ ทำการคำนวณหาระยะห่าง หรือ Euclidean Distance ของ data point กับ centroid ในแต่ละกลุ่ม ผลที่ได้คือจุดข้อมูลที่อยู่ใกล้กับศูนย์กลางไหนมากที่สุด ก็จะถูกจัดให้อยู่กลุ่มเดียวกันกับศูนย์กลางนั้น ข้อควรระลึกในแบบนี้ คือ ผลลัพธ์จากการใช้ k-means ในแต่ละครั้งจะไม่เหมือนกันเนื่องจากการกำหนด centroid ในขั้นแรกสุดนั้นเป็นการสุ่ม
2. การแบ่งกลุ่มของข้อมูลเกิดจากการกระจุกตัวของจุดข้อมูล (Density-based Clustering) คือ การที่จุดข้อมูลวางตัวเกาะกลุ่มกันอย่างหนาแน่นและไม่เป็นรูปลักษณ์ที่ตายตัว อุปสรรคของการแบ่งกลุ่มนี้ คือ ความหนาแน่นที่ผันผวนและจำนวน feature ของชุดข้อมูล นอกจากนี้ยังแยก outlier ออกจากกลุ่มได้ชัดเจนด้วย ถือว่าข้อดีและเป็นการแก้ข้อบกพร่องของ centroid-based model ที่ sensitive กับ outlier ซึ่ง algorithm ที่นิยมใช้ คือ DBSCAN (Density-Based Spatial Clustering of Applications with Noise) ในขั้นแรก กำหนดรัศมีจากจุดศูนย์กลาง (eps) และจำนวน data point ขั้นต่ำในรัศมี (MinPts) จากนั้นถ้า data point ที่เป็นจุดศูนย์กลางรวมกับ data point ที่อยู่โดยรอบภายในวงรัศมีมีจำนวนเท่ากับ MinPts เราจะเรียก data point จุดนั้นว่า “core point” ส่วน “border” คือ data point ที่เป็นจุดศูนย์กลางและมี data point ที่อยู่โดยรอบกับ core point หรือ border ด้วยกันเอง พูดง่าย ๆ คือจะรวมจุดที่เป็นเพื่อนของเพื่อนของเพื่อนไปเรื่อย ๆ จนไม่มีเพื่อนให้จับกลุ่มอีกแล้ว ก็จะถือว่าสิ้นสุดการจับกลุ่ม ส่วนจุดที่ไม่ถูกจับรวมกลุ่มเพราะอยู่ไกลเกินไปจะถือว่าเป็น outlier หรือ noise
3. การแบ่งกลุ่มแบบการกระจาย (Distribution-based Clustering) ข้อมูลจะมีรูปแบบการแจกแจงแบบใดแบบหนึ่ง เช่น การแจกแจงปกติ (Normal Distributions) เมื่อระยะห่างระหว่างจุดศูนย์กลางของการแจกแจง กับ data point เพิ่มมากขึ้น ความน่าจะเป็นที่ data point เป็นส่วนหนึ่งของการแจกแจงนั้นจะลดลง แต่ถ้าเราไม่ทราบว่าข้อมูลมีการแจกแจงแบบใด ก็ควรเลือกใช้การ clustering รูปแบบอื่น ซึ่ง algorithm ที่เป็นตัวอย่าง คือ Expectation-maximization algorithm หรือเรียกว่า EM algorithm ซึ่งมีการทำงานแบบ iterative ระหว่าง 2 โหมด คือ E-Step ประมาณการค่าของตัวแปรที่หายไปจากชุดข้อมูล และ M-Step เพิ่มประสิทธิภาพพารามิเตอร์ของโมเดล
4. การแบ่งกลุ่มแบบ (Hierarchical Clustering) การแบ่งกลุ่มประเภทนี้ จะสร้างให้เกิดในรูปของภาพต้นไม้ของกลุ่มข้อมูล เหมาะสำหรับข้อมูลที่มีลำดับชั้น เช่น อนุกรมวิธาน (Taxonomy) การแบ่งกลุ่มลักษณะนี้มี 2 ประเภท คือ
- แบบล่างขึ้นบน (Agglomerative) ในเริ่มแรกจุดเริ่มข้อมูลนับเป็นหนึ่ง cluster จากนั้นจะคำนวณหาค่าความใกล้ชิด cluster ที่อยู่ใกล้กันจะถูกจับรวมตัวกัน และจะวนทำเช่นนี้ไปเรื่อย ๆ จนกว่าจะกลายเป็น cluster เดียวในที่สุด แผนภาพที่ถูกใช้นำเสนอการทำ cluster เช่นนี้ คือ Dendrogram
- แบบบนลงล่าง (Divisive) จะทำตรงกันข้ามกับแบบ Agglomerative คือ เริ่มจาก cluster กลุ่มใหญ่กลุ่มเดียว และแยกกลุ่มที่ไม่เหมือนกันออกไปเรื่อย ๆ จะเป็นเป็น n กลุ่มที่แยกต่อไม่ได้แล้ว ตัวอย่างกันใช้งาน เช่น การแบ่งกลุ่มพืช หรือสิ่งมีชีวิต, การแบ่งกลุ่มสินค้า
จะพบว่าที่กล่าวมาเป็นเพียงบางส่วนที่ใช้ในการจัดกลุ่ม มีทำได้หลากหลายวิธีควรที่จะต้องเลือกใช้การแบ่งที่เหมาะสมกับโจทย์ปัญหาที่เราสนใจ เมื่อเราแบ่งกลุ่มแล้ว ขั้นตอนต่อไปคือการประเมินกลุ่มที่เราจัดแบ่ง ว่ามีคุณภาพเป็นอย่างไรเราสามารถปรับพารามิเตอร์ เพื่อให้กลุ่มที่จัดดีขึ้น
.
----------------------
ที่มาข้อมูล
-
รวบรวมรูปภาพ
-----------------------
เทคโนโลยีสารสนเทศ (Information Technology)
ปัญญาประดิษฐ์ (Artificial Intelligence, AI) รวมข้อมูลทั้งหมด
ความเชื่อมโยง 3 เทคโนโลยีในงานสารสนเทศ
-----------------------
.