ขั้นตอนการฝึกอบรมสำหรับ ChatGPT (training process)
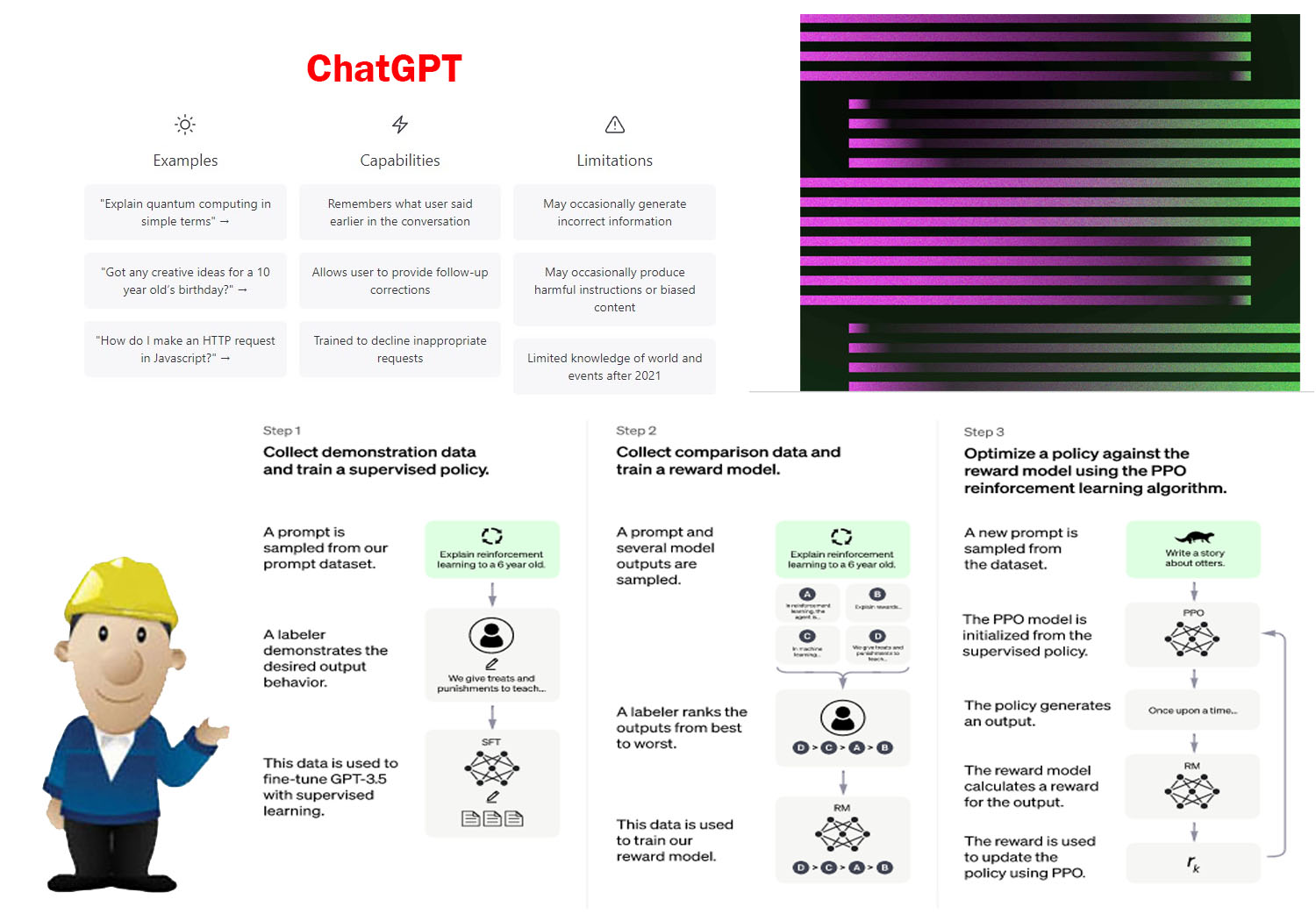
ขั้นตอนการฝึกอบรมสำหรับ ChatGPT (training process) มีหลายรูปแบบตามแนวทางผู้จัดทำในแต่ละที่ โดยส่วนใหญ่จะพบว่ามีขั้นตอนการทำงานที่ใช้ในการสอนระบบ AI เบื้องต้นที่พบ ได้แก่
1. การรวบรวมข้อมูล (Data collection) ในการฝึก ChatGPT จะมีการรวบรวมชุดข้อมูลขนาดใหญ่ของข้อความจากแหล่งต่างๆ ชุดข้อมูลนี้ ประกอบด้วยข้อมูลที่หลากหลาย เช่น หนังสือ บทความ เว็บไซต์ และแหล่งข้อความอื่นๆ จากอินเทอร์เน็ต ข้อมูลได้รับการคัดเลือกมาอย่างดี เพื่อให้แน่ใจว่าครอบคลุมหัวข้อและสไตล์ที่หลากหลาย
2. การเตรียมประมวลผลเบื้องต้น (Preprocessing) ข้อมูลที่รวบรวมจะได้รับการประมวลผลในชั้นตอนนี้ เพื่อทำความสะอาดข้อมูลและเตรียมพร้อมสำหรับใช้ในการฝึกอบรม ในขั้นตอนนี้รวมถึงการทำความสะอาตข้อมูล การปรับแก้ไขและลบข้อมูลที่ไม่เกี่ยวข้อง หรืออาจมีปัญหาที่ผิดพลาดสัญญาณรบกวน การจัดการอักขระพิเศษ โดยทั่วไปจะเกี่ยวข้องกับการลบข้อมูลที่ไม่เกี่ยวข้อง เช่น ข้อมูลเมตา ส่วนหัว ส่วนท้าย และโฆษณา ข้อความมักจะถูกทำให้เป็นมาตรฐานโดยการจัดการเครื่องหมายวรรคตอน อักขระพิเศษ และการจัดรูปแบบที่ไม่สอดคล้องกัน ก่อนจะทำโทเค็น (tokenizing) ข้อความให้เป็นหน่วยที่เล็กลง เช่น คำหรือคำย่อย และจัดปรับรูปแบบของข้อมูลให้เป็นโมเดลที่สามารถประมวลผลได้
3. ออกแบบจำลองสถาปัตยกรรม (Model architecture) โดยทั่วไปแล้วโมเดล GPT จะใช้สถาปัตยกรรมแบบ Transformer ซึ่งประกอบด้วย โครงข่ายประสาทเทียมที่ให้ความสนใจในตัวเองและนำเข้าจัดการในหลายชั้น (multiple layers of self-attention and feed-forward neural networks) ลักษณะเฉพาะของสถาปัตยกรรม เช่น จำนวนเลเยอร์ หน่วยที่ซ่อนอยู่ ความสนใจ ฯลฯ อาจแตกต่างกันไปขึ้นอยู่กับเวอร์ชันของรุ่น
4. การเริ่มต้นแบบจำลอง (model is initialized) ก่อนการฝึกเริ่มต้น พารามิเตอร์ของโมเดล น้ำหนักและอคติ (weights and biases) จะถูกเริ่มต้นแบบสุ่ม จะเริ่มต้นด้วยจัดน้ำหนักสุ่มก่อนเริ่มการฝึก การเริ่มต้นแบบสุ่มนี้ช่วยให้กระบวนการฝึกอบรมในภายหลัง สามารถปรับเปลี่ยนน้ำหนักตามข้อมูลที่ป้อนเข้าได้ การเริ่มต้นแบบสุ่มนี้ ช่วยให้กระบวนการฝึกอบรมที่ตามมาสามารถแก้ไขพารามิเตอร์ตามข้อมูลที่ป้อนเข้าและปรับค่าให้เหมาะสมที่สุด
5. จัดฝึกอบรมในรูปแบบวนซ้ำ (Training loop) ลูปการฝึกอบรมเกี่ยวข้องกับการนำเสนอข้อมูล ที่ประมวลผลล่วงหน้าซ้ำๆ ไปยังโมเดลและปรับน้ำหนัก เพื่อลดความแตกต่างระหว่างการคาดการณ์ของโมเดลและผลลัพธ์ที่ต้องการ กระบวนการปรับให้เหมาะสมโดยทั่วไปจะใช้อัลกอริธึมการไล่ระดับสีแบบไล่ระดับสี เช่น การลงแบบไล่ระดับสีแบบสุ่ม (SGD) หรือรูปแบบต่างๆ
6. การขยายผลกลับ (Backpropagation) ในระหว่างการฝึกมีข้อผิดพลาดหรือการสูญเสีย ระหว่างการคาดคะเนของแบบจำลองและผลลัพธ์ที่ต้องการจะถูกคำนวณ จากนั้นข้อผิดพลาดนี้จะถูกส่งกลับผ่านชั้นต่างๆ ของโมเดล โดยปรับน้ำหนักตามการไล่ระดับสีของข้อผิดพลาดตามน้ำหนัก ขั้นตอนนี้ทำให้โมเดลสามารถเรียนรู้จากข้อผิดพลาดและปรับปรุงประสิทธิภาพเมื่อเวลาผ่านไป
7. การฝึกวนซ้ำ (Iterative training) การฝึกซ้ำสำหรับการวนซ้ำหลายครั้ง โดยที่แต่ละครั้งเกี่ยวข้องกับการนำเสนอชุดข้อมูลทั้งหมดไปยังโมเดล ทำให้โมเดลสามารถเรียนรู้จากตัวอย่างที่หลากหลายและค่อยๆ ปรับแต่งความเข้าใจในข้อมูล ชุดข้อมูลการฝึกอบรมทั้งหมดจะแสดงต่อโมเดลเป็นชุดย่อย และพารามิเตอร์จะได้รับการอัปเดตตามนั้น การทำขั้นตอนนี้ซ้ำจะทำให้โมเดลเห็นตัวอย่างต่างๆ และค่อยๆ เรียนรู้รูปแบบและความสัมพันธ์ในข้อมูล จำนวนรอบอาจแตกต่างกันไปขึ้นอยู่กับปัจจัยต่างๆ เช่น ขนาดของชุดข้อมูล ทรัพยากรการคำนวณที่มีอยู่ และระดับความสนใจที่ต้องการ
8. การปรับไฮเปอร์พารามิเตอร์ (Hyperparameter tuning) ตลอดกระบวนการฝึกอบรม ไฮเปอร์พารามิเตอร์ต่างๆ จะถูกปรับและปรับแต่งเพื่อเพิ่มประสิทธิภาพการทำงานของโมเดล ไฮเปอร์พารามิเตอร์เหล่านี้รวมถึงอัตราการเรียนรู้ ขนาดแบทช์ เทคนิคการทำให้เป็นมาตรฐาน และอื่นๆ การปรับไฮเปอร์พารามิเตอร์เหล่านี้อาจมีผลกระทบอย่างมากต่อประสิทธิภาพขั้นสุดท้ายของโมเดล
9. การประเมิน (Evaluation) ประสิทธิภาพของโมเดลจะได้รับการประเมินในชุดข้อมูลการตรวจสอบแยกต่างหากเป็นระยะๆ เพื่อติดตามความคืบหน้าและกำหนดว่าเมื่อใดควรหยุดการฝึก สามารถใช้เมตริกต่างๆ เช่น ความฉงนสนเท่ห์หรือความแม่นยำ เพื่อประเมินคุณภาพของแบบจำลองได้ ประสิทธิภาพของแบบจำลองจะได้รับการประเมินในชุดข้อมูลการตรวจสอบแยกต่างหาก ที่ไม่ได้ใช้ในระหว่างการฝึกอบรม การประเมินนี้ช่วยติดตามความคืบหน้าของโมเดล ตรวจหา overfitting (เมื่อโมเดลมีความเฉพาะเจาะจงกับข้อมูลการฝึกมากเกินไป) และกำหนดว่าเมื่อใดควรหยุดการฝึก เมตริกต่างๆ ใช้เพื่อประเมินคุณภาพของแบบจำลอง เช่น ความฉงนสนเท่ห์การวัดว่าแบบจำลองคาดการณ์โทเค็นถัดไปได้ดีเพียงใด หรือความแม่นยำสำหรับงานการจัดประเภท
10. การปรับใช้ (Deployment) เมื่อแบบจำลองได้รับการฝึกอบรมและประเมินอย่างน่าพอใจแล้ว สามารถนำไปใช้เพื่อตอบสนองต่อคำถามของผู้ใช้และมีส่วนร่วมในการสนทนา กระบวนการปรับใช้เกี่ยวข้องกับการรวมโมเดลที่ผ่านการฝึกอบรมเข้ากับแอปพลิเคชันหรือระบบที่โต้ตอบกับผู้ใช้ โดยให้การตอบสนองตามความรู้และความเข้าใจที่ได้เรียนรู้ของโมเดล
เป็นที่น่าสังเกตว่าขั้นตอนเหล่านี้เป็นโครงร่างทั่วไปของกระบวนการฝึกอบรม แต่รายละเอียดและเทคนิคเฉพาะที่ OpenAI ใช้ในการฝึกอบรม ChatGPT อาจเป็นกรรมสิทธิ์และขึ้นอยู่กับการวิจัยและพัฒนาในแต่ละที่ กระบวนการฝึกอบรมควรมีการทำอย่างต่อเนื่อง โมเดลที่ดีควรจะได้รับการอัปเดตและปรับปรุงอย่างต่อเนื่อง เมื่อมีข้อมูลมากขึ้นและมีการพัฒนาเทคนิคการฝึกอบรมใหม่ๆ ระบบก็จะมีความถูกต้องแม่นยำมากขึ้นได้
อยากรู้ว่า ChatGPT เป็นอย่างไรดูได้ที่ https://beta.openai.com/ หรือ https://openai.com/api/
.
----------------------
ที่มาข้อมูล
-
รวบรวมรูปภาพ
-----------------------
เทคโนโลยีสารสนเทศ (Information Technology)
ปัญญาประดิษฐ์ (Artificial Intelligence, AI) รวมข้อมูลทั้งหมด
ความเชื่อมโยง 3 เทคโนโลยีในงานสารสนเทศ
-----------------------
.