Big Data ระบบข้อมูลขนาดใหญ่ (Big Data Platform)
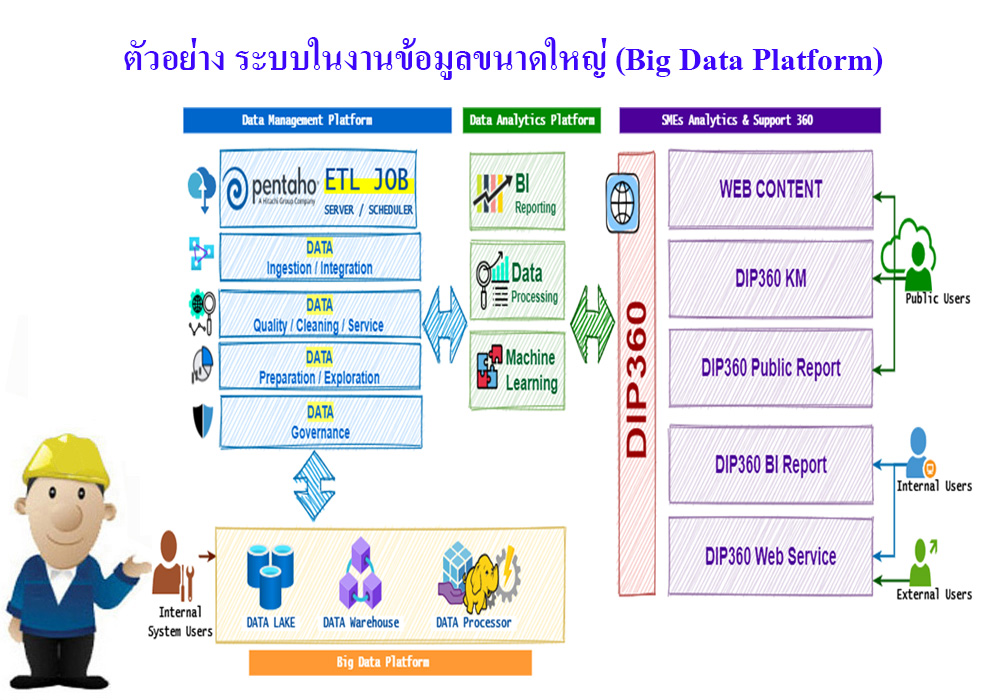
ระบบข้อมูลขนาดใหญ่ (Big Data Platform) ควรมีความสามารถในการดำเนินการด้านข้อมูลที่รอบด้านและครอบคลุม พร้อมรับข้อมูลที่เพิ่มมากขึ้นอย่างรวดเร็ว รวมถึงรองรับการพัฒนาด้านเทคโนโลยีด้านข้อมูลที่จะเกิดในอนาคต แพลตฟอร์มฐานข้อมูลจำเป็นต้องรองรับการประมวลผลบิ๊กดาต้าได้อย่างรวดเร็ว และรองรับการขยายระบบในอนาคต และต้องมีเซอร์วิสที่ครอบคลุมให้บริการการดำเนินการด้านข้อมูลที่จำเป็นและที่จะเกิดขึ้นในอนาคต รวมถึงระบบบริหารจัดการผู้ใช้งาน ระบบรักษาความปลอดดภัยที่ได้มาตรฐานสากล
ระบบข้อมูลขนาดใหญ่ (Big Data Platform) ประกอบไปด้วยงาน 4 ด้าน คือ
การรวบรวมและจัดการ (Data Ingestion/Collection)
การจัดเก็บข้อมูล (Data Storage)
การประมวลผลข้อมูล (Data Processing)
การนำเสนอข้อมูลรายงาน (Data Visualisation)
หลักในการทำงานระบบข้อมูลขนาดใหญ่ จะเน้นในการสร้างพื้นที่จัดเก็บข้อมูลหรือที่เราเรียกว่าทะเลสาบข้อมูล (Data Lake) เพื่อที่จะนำเอาข้อมูลที่มีปริมาณมหาศาลจากในที่ต่าง ๆ ผ่านระบบเทคโนโลยีสารสนเทศ มาทำการจัดเก็บรวบรวมไว้ในคลังข้อมูล โดยอาจจะเป็นข้อมูลในการทำธุรกรรมต่าง ๆ ขององค์กร ข้อมูลจากสื่อโชเชี่ยลและเครือข่ายอินเอตร์เน็ต รวมถึงข้อมูลจากระบบ IoT ซึ่งข้อมูลเหล่านี้จะพบว่ามีปริมาณที่มากมายมหาศาลในหลากหลายรูปแบบ จึงเป็นที่มาของคำว่าข้อมุลขนาดใหญ่
การที่ต้องเก็บมีการจัดการกับข้อมูลเป็นจำนวนมาก และมีการนำข้อมูลที่เก็บมาทำการประมวลผลในเวลารวดเร็ว จึงเป็นความท้าทายที่ต้องหาหน่วยในการจัดเก็บข้อมูล (Storage) ที่เหมาะสมและมีขนาดใหญ่เพียงพอ และต้องขยายได้อย่างรวดเร็ว มีราคาถูก และมีความเสถียร จึงเป็นไปได้ยากที่บางหน่วยงานจะพัฒนาระบบแบบ On-Premise เพราะในอนาคตต้องขยายระบบไปเรื่อย ๆ เพื่อเก็บข้อมูลที่มีขยายต่อเนื่องไปทั้งหมด ดังนั้นแนวทางที่ดีคือการเก็บข้อมูลขนาดใหญ่ไว้บน Public Cloud Storage ที่จะตอบโจทย์เหลือราคาความเสถียรและขนาดการเก็บได้ดีกว่า เช่น การใช้ Amazon S3, Azure Data Lake Storage (ADLS) และ Google Cloud Storage เป็นต้น แล้วก็นำข้อมูลที่จะเป็นที่อาจมีความสำคัญอย่างมาก ที่ไม่อยากนำไปเก็บออกนอกองค์กรมาใส่ไว้ใน Storage ของ Hadoop HDFS ที่เราอาจติดตั้งระบบ Cluster ขนาดเหมาะสมไว้ในองค์กร (On-Premise) แต่ไม่จำเป็นต้องเป็นระบบที่ใหญ่มากนัก
ในแง่ของการประมวลผลข้อมูล (Data Processing) เราสามารถที่จะใช้ Hadoop On-Premise มาทำการประมวลโดยผ่านเทคโนโลยีอย่าง Spark, Hive หรือเครื่องมืออื่น ๆ แต่ความท้าทายก็อาจจะอยู่ที่เมื่อต้องการประมวลผลข้อมูลที่ใหญ่มาก ๆ เช่น การทำ Machine Learning กับข้อมูลที่อาจมีขนาดใหญ่มาก ซึ่งจำเป็นต้องการระบบประมวลผลที่ดีรวดเร็วมีประสิทธิภาพ ส่วนใหญ่จะมีการสร้างระบบแบ่งเป็น Cluster แยกมาช่วยกันทำงาน ควรที่จะมี CPU จำนวนมากในการทำงาน ซึ่งระบบ On-Premise อาจไม่สามารถรองรับได้ดีพอ ในบางครั้งก็อาจต้องใช้บริการที่มีบน Public Cloud มาช่วย เราสามารถกำหนด CPU จำนวนมากได้ หรือบางครั้งก็อาจใช้บริการประมวลผลอื่นที่มีอยู่บน Public cloud ซึ่งสามารถช่วยในการประมวลผลอย่างรวดเร็วได้อย่าง เช่น Google BigQuery, Azure ML, AWS Athena ก็จะทำให้ได้ประสิทธิภาพดีมากขึ้น ข้อดีของการประมวลผลแบบนี้คือจะมีราคาขึ้นอยู่กับการใช้งานจริงสามารถปรับเปลี่ยนเพิ่มลดได้ง่าย ในบางครั้งจะมีราคาที่ถูกกว่าติดตั้งระบบขององค์กรได้
ในด้านการดึงข้อมูลเข้ามาทำการจัดเก็บ ทีม Data Ingestion ก็ต้องพิจารณาต้นทางข้อมูลว่าจัดเก็บอยู่ที่ใด ถ้าข้อมูลที่จะนำเข้ามาในระบบส่วนใหญ่อยู่ในองค์กร ก็ควรที่จะตั้งระบบแบบ On-Premise แต่ถ้าส่วนใหญ่อยู่ภายนอกก็อาจใช้ Public cloud service ส่วนการเลือกใช้เครื่องมือด้าน Visualisation ที่อาจต้องมีทั้งสองระบบ โดยระบบ On-Premise ใช้กับการแสดงข้อมูลภายในองค์กรผ่าน Desktop ส่วนกรณีแสดงผลผ่านเว็บหรืออินเตอร์เน็ตอาจพิจารณาใช้ Public cloud มาช่วยต่อไป
ระบบข้อมูลขนาดใหญ่ (Big Data Platform) ควรมีคุณสมบัติดังนี้
- ต้องสามารถจัดเก็บและประมวลผลบิ๊กดาต้าได้อย่างมีประสิทธิภาพ
- ต้องรองรับการพัฒนาด้านเทคโนโลยีที่จะเกิดในอนาคตอันใกล้
- ต้องรองรับการขยายในอนาคต
- ต้องมีบริการที่ครอบคลุมให้บริการการดำเนินการด้านข้อมูลที่จำเป็นและที่สามารถเกิดขึ้นในอนาคตอันใกล้
- ต้องมีระบบรักษาความปลอดภัยที่มีมาตรฐาน และระบบการบริหารจัดการผู้ใช้งาน กำหนดกลุ่มและสิทธิของผู้ใช้งาน
----------------------------------------------------------------
สนใจข้อมูลเพิ่มเติมดูที่
Big Data รวมข้อมูลและเรื่องราวที่เกี่ยวกับข้อมูลขนาดใหญ่ (Big Data)