Big Data นิยามคำศัพท์ บิ๊กดาต้า (Big Data Definition)
Big Data นิยามคำศัพท์ บิ๊กดาต้า (Big Data Definition)
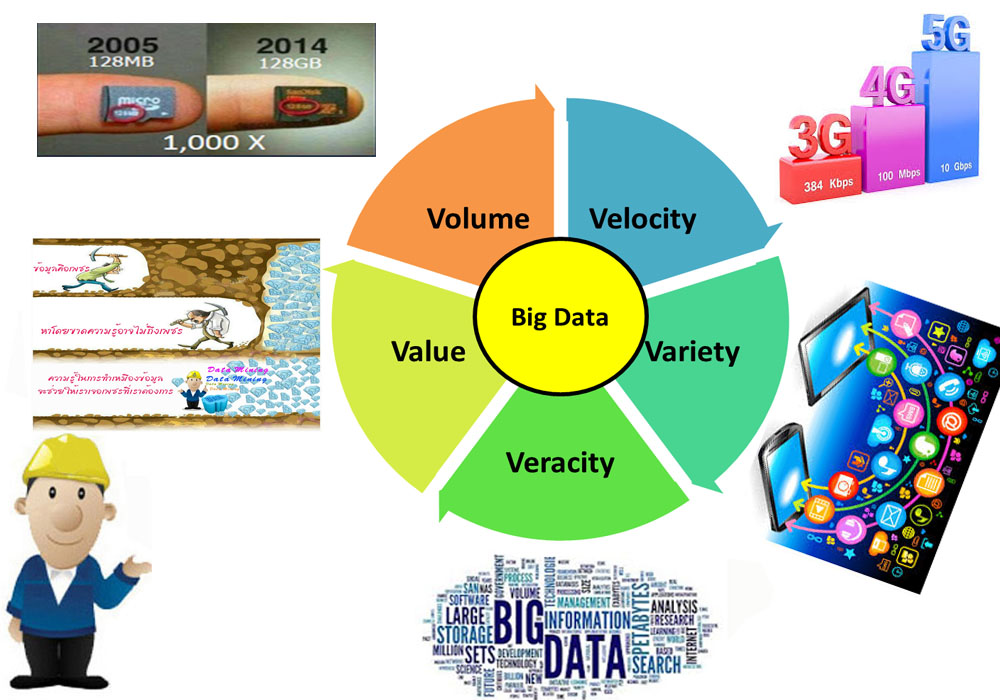
บิ๊กดาต้า (Big Data) หมายถึง กลุ่มของข้อมูลขนาดใหญ่ ที่มีความหลากหลาย ทั้งรูปแบบที่จัดเก็บ สามารถรองรับข้อมูลแบบมีโครงสร้าง กึ่งโครงสร้าง และไม่มีโครงสร้างได้ รวมทั้งมีเครื่องมือที่รองรับความเร็วในการจัดเก็บข้อมูล ได้ทั้งแบบ Batch และแบบ Real time
ปัญญาประดิษฐ์ (Artificial Intelligence) หรือ AI หมายถึง การศึกษาทางวิทยาการคอมพิวเตอร์แขนงหนึ่ง ที่เกี่ยวข้องกับกระบวนการทำให้คอมพิวเตอร์สามารถคิดหาเหตุผล เรียนรู้ และทำงานได้เหมือนสมองมนุษย์
Batch หมายถึง กลุ่ม หรือ ชุดข้อมูล ที่รวบรวมเข้ามาจัดเก็บและประมวลผลในระบบฐานข้อมูลพร้อมกัน
บิ๊กดาต้าแพลตฟอร์ม (Big Data Platform) หมายถึง ระบบที่รวมเทคโนโลยีบิ๊กดาต้า บริการพื้นฐาน และเครื่องมือต่างๆ เพื่อให้บริการผู้ใช้ในระบบเดียวในลักษณะ Platform as a Service (PaaS) หรือการให้บริการในระดับแพลตฟอร์ม (Platform)
ระบบบริหารจัดการข้อมูลขนาดใหญ่ (Big Data Management) หมายถึง ระบบที่เกี่ยวข้องกับงานด้านการบริหารและจัดการข้อมูลขนาดใหญ่ทั้งหมด ตั้งแต่การนำเข้าข้อมูล (Data Ingestion) การบูรณาการข้อมูล (Data Integration) การเปลี่ยนแปลงข้อมูล (Data Transformation) การเตรียมข้อมูล (Data Preparation) การบริกรข้อมูล (Data Stewardship) การบริการข้อมูล (Data Service) การกำกับดูแลและธรรมมาภิบาลข้อมูล (Data Governance) ที่ดูแลเรื่องความปลอดภัยและความเป็นส่วนตัวของข้อมูล (Data Security & Privacy)
BI Tool หมายถึง เครื่องมือสำหรับงานด้าน Business Intelligence (BI) ที่ใช้สำหรับนำข้อมูลที่มีอยู่ เพื่อจัดทำรายงานในรูปแบบต่างๆ และใช้แสดงมุมมองในการวิเคราะห์ แสดงความสัมพันธ์ และทำนายผลลัพธ์ของแนวโน้มที่อาจเกิดขึ้นได้ ตรงตามความต้องการขององค์กร เพื่อประโยชน์ในการวางแผนกลยุทธด้านต่างๆ
ระบบวิเคราะห์และทำรายงาน (Data Analytics and Visualization) หมายถึง ระบบที่เกี่ยวข้องกับงานด้านการวิเคราะห์ข้อมูลและแสดงข้อมูลและผลการวิเคราะห์ข้อมูล รวมถึงเครื่องมือต่างๆที่ใช้สำหรับการวิเคราะห์ การทำโมเดล Machine Learning การทำรายงานและ Dashboard และเครื่องมือสำหรับการแสดงผลที่เป็นแผนภาพ แผนที่และกราฟต่างๆ เป็นต้น
Data Dictionary หมายถึง พจนานุกรมข้อมูล ที่แสดงรายละเอียดตารางและความหมายของข้อมูลต่างๆ เช่น ชื่อข้อมูล (Relation Name) แอตทริบิวต์ (Attribute) ชนิดของข้อมูล (Data Type) รายละเอียดข้อมูล (Data Description) และชื่อโดเมน (Domain) เป็นต้น
Data Lake หมายถึง แหล่งจัดเก็บบิ๊กดาต้าบนระบบบิ๊กดาต้าแพลตฟอร์ม ซึ่งถูกออกแบบสำหรับจัดเก็บข้อมูลดิบที่มาจากแหล่งข้อมูลต่างๆ ของ บิ๊กดาต้าได้
Data Mart หมายถึง แหล่งจัดเก็บข้อมูลสำหรับการบริการข้อมูล (Data Service) ปกติข้อมูลส่วนนี้จะมาจาก Data warehouse แล้วนำมาจัดหมวดหมู่ตามจุดประสงค์ของการใช้งานและประโยชน์ โดยสามารถจัดทำเป็นข้อมูลที่มีมูลค่าสูง (High-valued Data) สำหรับนำไปใช้วิเคราะห์และทำรายงาน หรือทำเป็นข้อมูลสาธารณะ (Public Data) สำหรับการบริการแก่ผู้ใช้ข้อมูลทั่วไป
Data Service หมายถึง การให้บริการข้อมูลในรูปแบบต่างๆ เช่น บริการข้อมูลบนเว็บ (Web Service) หรือ Web APIs (Application Program Interface) เป็นต้น เพื่อใช้สำหรับเป็นช่องทางเชื่อมต่อและแลกเปลี่ยนข้อมูลระหว่างหน่วยงานต่างๆ ด้วยรูปแบบที่เป็นมาตรฐาน
Data Warehouse หมายถึง แหล่งจัดเก็บข้อมูลคุณภาพสูงในระบบบิ๊กดาต้าแพลตฟอร์ม ที่ข้อมูลถูกออกแบบให้เป็นข้อมูลแบบมีโครงสร้าง ผ่านกระบวนการตรวจสอบคุณภาพข้อมูล การทำความสะอาดข้อมูล การดัดแปลงโครงสร้าง และจัดรูปแบบให้ได้มาตรฐาน โดยปกติจะถูกออกแบบมา เพื่อให้นักวิเคราะห์ข้อมูลและนักวิทยาศาสตร์ข้อมูล นำไปใช้ในการวิเคราะห์และทำรายงานผลการวิเคราะห์
Descriptive Analytics หมายถึง รูปแบบการวิเคราะห์ข้อมูลแบบพื้นฐาน โดยอาศัยสถิติเชิงพรรณนา มุ่งเน้นที่จะสรุปข้อมูลและนำเสนอเชิงสถิติเพื่อรายงานถึงสิ่งที่เกิดขึ้นจากข้อมูลที่มีอยู่ในอดีตจนถึงปัจจุบัน
ETL (Extract Transform Load) หมายถึง กระบวนการนำเข้าข้อมูลจากแหล่งข้อมูลต้นทาง (Data Source) ที่ต้องมีการเปิดหรือเข้าถึงชุดข้อมูล (Extract) ต่างๆ แล้วทำการเปลี่ยนสภาพข้อมูล (Transform) ให้อยู่ในรูปแบบที่ต้องการ ก่อนจะนำข้อมูลไปจัดเก็บ (Load) ในแหล่งข้อมูลปลายทาง (Data Source)
ETL Tool หมายถึง อุปกรณ์หรือเครื่องมือสำหรับการจัดการโปรแกรมงาน ETL (ETL Job) เช่น ใช้สำหรับสร้างโปรแกรม รันโปรแกรม และการจัดตารางการรันโปรแกรม เป็นต้น
Hadoop หมายถึง ระบบซอฟต์แวร์สำหรับบริหารจัดการบิ๊กดาต้าชนิดหนึ่ง ซึ่งพัฒนามาจากระบบแบบกระจาย (Distributed System) โดยมีบริการพื้นฐานในการจัดเก็บและประมวลผลข้อมูลแบบกระจาย (Parallel Computing) รวมทั้งส่วนบริหารจัดการงานในระบบแบบกระจายให้มีประสิทธิภาพ
HBase หมายถึง ระบบฐานข้อมูลใน Hadoop ที่สนับสนุนการจัดเก็บแบบ NoSQL
Hive หมายถึง ระบบฐานข้อมูลและการประมวลผลข้อมูลแบบ SQL ใน Hadoop ซึ่งใช้การแปลงคำสั่ง SQL ให้เป็น MapReduce Job เพื่อไปประมวลผลแบบขนานต่อไป
HDFS หมายถึง ระบบจัดการไฟล์แบบกระจายของ Hadoop (Hadoop Distributed Filesystem)
Impala หมายถึง ระบบฐานข้อมูลและการประมวลผลข้อมูลแบบ SQL ใน Hadoop พัฒนาโดยบริษัท Cloudera ซึ่งมีประสิทธิภาพสูงกว่า Hive เนื่องจากไม่ต้องเสียเวลาในการแปลง SQL เป็น MapReduce Job
Kafka หมายถึง ระบบบริหารจัดการ Streaming Data ใน Hadoop ให้ผู้รับและผู้ส่ง สามารถรับส่งข้อมูลระหว่างกันแบบ Real-time ได้อย่างมีประสิทธิภาพ
Kudu หมายถึง ระบบจัดเก็บข้อมูลใน Hadoop แบบมีโครงสร้าง ที่สนับสนุนการจัดเก็บข้อมูลแบบสุ่ม (Random Access) ออกแบบมาสำหรับข้อมูลแบบ Transaction ที่เหมาะสำหรับการแก้ไขบ่อยๆ เหมาะสำหรับการนำไปวิเคราะห์ได้อย่างมีประสิทธิภาพ
Machine Learning หมายถึง กระบวนการและวิธีการในระบบ AI ที่ทำให้เครื่องคอมพิวเตอร์สามารถเรียนรู้ได้จากตัวอย่างด้วยตนเอง โดยปราศจากการป้อนคำสั่งของมนุษย์ รวมถึงกระบวนการที่ทำให้คอมพิวเตอร์สามารถคิดหาเหตุผล เรียนรู้ และทำงานได้เหมือนสมองมนุษย์
MapReduce หมายถึง บริการพื้นฐานของ Hadoop ที่สนับสนุนการประมวลผลแบบขนาน โดยแบ่งการทำงานเป็น 2 ขั้นต้อน ได้แก่ Map เป็นการแบ่งบิ๊กดาต้าออกเป็นหลายชุดและนำไปประมวลผลแบบขนานพร้อมกัน และ Reduce เป็นการรวมผลลัพธ์ที่ได้จากการประมวลผลแบบขนานให้เป็นผลลัพธ์/ข้อมูลเดียวกัน
Metadata หมายถึง ข้อมูลสรุป หรือคำอธิบายของข้อมูลใดข้อมูลหนึ่ง เพื่อจะใช้จัดเก็บและทำการค้นหาและนำข้อมูลมาใช้งานได้อย่างง่ายดาย เช่น ชื่อชุดข้อมูล คำอธิบายข้อมูล คำสำหรับสืบค้น เจ้าของข้อมูล วันที่สร้างขึ้น วันที่เปลี่ยนแปลง ความถี่ในการอัพเดท และ ขนาดของข้อมูลเป็นต้น
Predictive Analytics หมายถึง รูปแบบการวิเคราะห์ข้อมูล ที่เน้นการพยากรณ์หรือทำนายอนาคต มุ่งเน้นที่จะพยากรณ์ข้อมูลที่ไม่มีอยู่จากข้อมูลที่มีอยู่ เพื่อรายงานถึงสิ่งที่น่าจะเป็นหรือสิ่งที่น่าจะเกิดขึ้น การวิเคราะห์ข้อมูลประเภทนี้จะเน้นการวิเคราะห์หาความสัมพันธ์ เพื่อสร้างโมเดล (model) ตัวแทนของความสัมพันธ์ดังกล่าวเพื่อใช้ในการพยากรณ์ต่อไป โดยอาศัยกระบวนการทำ Machine Learning
Real time หมายถึง การนำเข้าข้อมูล หรือการประมวลผลข้อมูลแบบทันที
Solr หมายถึง บริการค้นหาข้อมูลในระบบ Hadoop ที่ใช้เทคนิคการค้นหาร่วมกับบริการ Lucense ซึ่งเป็นการทำดัชนีแบบย้อนกลับ (Inverted Indexing) ทำให้สามารถค้นหาบิ๊กดาต้าได้อย่างมีประสิทธิภาพ
Spark หมายถึง บริการประมวลผลข้อมูลแบบ Streaming Data ด้วยความเร็วสูง โดยใช้การประมวลผลในหน่วยความจำ (In-memory Processing)
Sqoop หมายถึง เครื่องมือการนำเข้าข้อมูลแบบมีโครงสร้างจากระบบฐานข้อมูลภายนอก เข้ามาจัดเก็บในระบบฐานข้อมูลภายใน Hadoop
SQL หมายถึง ภาษามาตรฐานที่ใช้ในการเรียกดูข้อมูลหรือประมวลผลข้อมูลแบบมีโครงสร้าง
Streaming Data หมายถึงข้อมูลที่มีการส่งผ่าน(Transfer) อย่างต่อเนื่องเป็นข้อมูลแบบ Real-time
NoSQL หมายถึง ภาษามาตรฐานที่ใช้ในการเรียกดูข้อมูลหรือประมวลผลข้อมูลแบบไม่มีโครงสร้าง
YARN หมายถึง บริการที่ช่วยในการบริหารจัดการทรัพยากรในระบบ Hadoop
----------------------------------------------------------------
สนใจข้อมูลเพิ่มเติมดูที่
Big Data รวมข้อมูลและเรื่องราวที่เกี่ยวกับข้อมูลขนาดใหญ่ (Big Data)